Dealing with Claim Denials in Healthcare Facilities

Healthcare providers have always been under a lot of pressure. Patient mix-ups, identity theft cases, denied claims, medical record errors, data breaches, and patient safety incidents are just a few examples of the challenges. However, all of these issues were more visible than ever with COVID-19. Claim denials were one of the most difficult challenges, as there were more patients in need of healthcare services during the pandemic’s peak. Both healthcare providers and payers were (and still be) at odds over denied claims, and the situation will only worsen as rules and regulations change. While hospitals are already suffering from massive losses, refused claims exacerbate the situation. That being said, let’s take a look at a few strategies for dealing with claim denials in healthcare facilities.
Strategies that can help reduce claim denials in healthcare
Provide training to the coding team
Coding errors are one of the most regular reasons for claim denials in healthcare facilities. For example, suppose a patient came in and requested healthcare services; the latter has a unique code. However, the coding team utilized the incorrect code, and when the payer inspects the claim, it is classified as denial because the incorrect code was used.
To avoid such errors, healthcare providers must train the coding team on topics such as common coding errors, coding do’s and don’ts, recent updates, and so on.
Ensure that physicians record information correctly
A lack of proper clinical documentation is another factor that contributes to claim denials in healthcare. The coding team is not responsible for every denied claim. When clinical documentation problems occur, wrong codes are almost always selected, resulting in denied claims.
As a result, healthcare providers must guarantee that physicians properly and timely record all paperwork in suitable medical records. RightPatient can aid in the proper identification of medical records and the reduction of denied claims.
Ensure that claims are submitted timely
Another reason contributing to denied claims is the failure to submit them on time, which can be easily rectified. Healthcare providers should set goals for their coding teams in order for them to process claims in a fast and accurate manner. They should, for example, categorize which batch of claims will be delivered and when they should be sent and check for errors.

While this does not always succeed, detecting the issues that cause late submissions can assist providers in addressing the issue and reducing future claim denials.
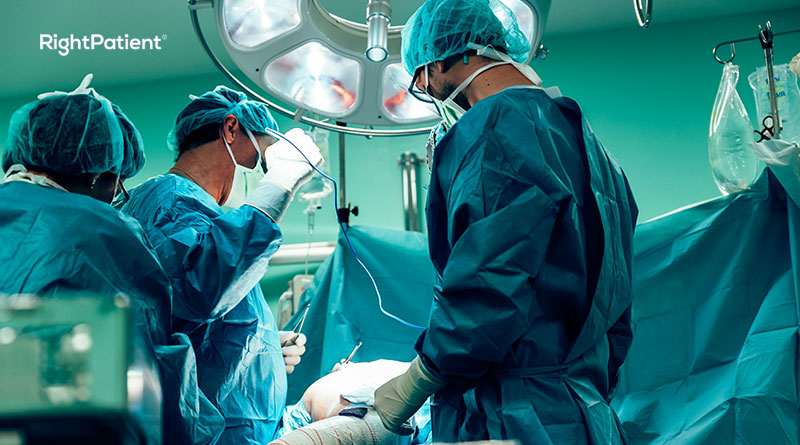
Ensure accurate patient identification to reduce denials in healthcare
One common cause of denials in healthcare facilities is medical record errors such as duplication and overlays, the majority of which result in mix-ups, improper treatment, and, predictably, billing and coding issues. The majority of medical record errors arise because there is no standardized patient identification in the US healthcare system.
While many healthcare providers waited for a standardized and effective patient identifier while dealing with duplication and denied claims, forward-thinking health systems already prevent them with RightPatient.
RightPatient is a touchless biometric patient identification platform used by top healthcare organizations such as Terrebonne General Medical Center, Duke Health, Community Medical Centers, and University Hospital. RightPatient uses one of the most secure, sanitary, and non-transferable properties of patients: their faces.
During registration, patients must look at the camera; RightPatient takes a snapshot and compares it to existing medical information to identify duplication. If no matches are identified, a new EHR is created with the patient’s photo attached. Whenever the patient comes to the hospital for additional healthcare services, they only need to look at the camera, And RightPatient generates the necessary medical record in seconds.
RightPatient isn’t just for registration; healthcare providers can use the platform throughout the care continuum. After scheduling sessions, remote patients can send selfie photographs as well as a photo of their ID card. RightPatient examines the photographs for a match, then searches to see if there are any existing records, and either produces new credentials for new patients or sends the proper EHR to the hospital for existing patients.
RightPatient not only makes accurate patient identification simple, but it’s also safe, secure, clean, and seamless. Healthcare providers may smoothly link RightPatient with their EHR systems, making the latter part of the EHR workflow.
Using RightPatient, some prominent healthcare providers reduce patient misidentification, eliminate duplicate medical records, minimize denied claims, and enhance patient safety and quality.